Preparing a Dataset for Instruction Tuning
Discover the process of fine-tuning an LLM using an instructional dataset! This guide will walk you through data formatting and model training, focusing on models such as Llama2, Mistral, etc. Here’s a minimal example implemented in (almost) pure PyTorch.
In this article, we’ll delve into the process of preparing your data for fine-tuning your LLM on instructions, also known as instruction tuning. We’ll guide you step-by-step through the formatting of your data and the application of preprocessing techniques necessary for successful model fine-tuning. This tutorial aims to simplify each step, ensuring a clear understanding of the underlying processes within these preprocessing pipelines. These steps are essential for debugging your fine-tuned large language model (LLM) later on.
NOTE: you can follow along with this notebook.

Framing The Project
An excellent resource, including a corresponding video, for comprehending Large Language Models (LLMs) is Karpathy’s nanoGPT repository. This repository offers a barebones implementation of the original GPT-2 architecture using PyTorch, featuring a minimalistic training loop suitable for functional parallel-compatible training scripts. Despite being primarily focused on completion tasks, it provides valuable insights into model training by processing large text corpora with a simplified data loading approach referred to as a “poor man’s dataloader.”
To adapt this code for instructional training or integrate pre-trained models like Llama 2 or Mistral, several steps are necessary. Firstly, leveraging libraries such as the HuggingFace transformers library becomes crucial. This widely used library facilitates handling models, datasets, and training processes and integrates seamlessly with tools like Weights & Biases (W&B), providing a comprehensive solution for model training and evaluation.
Another noteworthy library built on top of transformers is Axolotl, which has been tested extensively by the open-source community and offers advanced features. Under the hood, Axolotl employs various optimization techniques and dependencies such as transformers, peft, bitsandbytes, and deepspeed to enhance performance and functionality.
Implementing a minimal fine-tuning pipeline is an excellent approach to gaining a deeper understanding of the underlying processes involved in adapting LLMs to specific tasks. By delving into this process, we can unravel the intricacies of fine-tuning LLMs and gain valuable insights into their behavior and performance. Let’s embark on this journey to uncover the nuances of fine-tuning pipelines and their implications for model adaptation and performance optimization.
Choosing Your Instruction Dataset
An instruction dataset is a list of pairs: instruction and answer.
Instruction
Explain the concept of a bubble sort algorithm to a non-technical audience.
Answer
A bubble sort algorithm is a type of sorting algorithm that is used to sort elements in an array. It works by looking at each element of the array and comparing it to the next element. If the first element is bigger than the second element, they are swapped. This process is repeated until the whole array is sorted. This type of sorting is one of the simplest sorting algorithms, but it can be slow if the array has many elements.
Instruction
Make the second sentence shorter.
Context
Winter is usually the coldest season of the year. Snow is a common element during winter.
Answer
Winter is the coldest season, often accompanied by snow.whole array is sorted. This type of sorting is one of the simplest sorting algorithms, but it can be slow if the array has many elements.
Some instructions require context to produce the output!
Constructing a high-quality dataset is undeniably expensive and time-consuming, especially when considering interactions with Large Language Models (LLMs), such as ChatGPT. This is typically the primary mode of usage for LLMs.
Numerous high-quality instruction datasets exist, varying in formats and lengths. Some are meticulously crafted manually, like the Flan Collection and the Dolly15k dataset, while others are generated using LLMs, like the Alpaca dataset. The open-source community actively curates and augments datasets for fine-tuning and creating instruction models. Recent datasets such as OpenOrca, Platypus, and OpenHermes produce exceptionally high-quality fine-tuned models that perform well on leaderboards and various evaluation tasks.
In this article, we will focus on utilizing the Alpaca dataset and delve into the pre-processing and formatting steps necessary to train a LLama model.
What Is The Alpaca Dataset?
The Alpaca dataset is a synthetic dataset created by Stanford researchers, utilizing the OpenAI Davinci model to generate instruction/output pairs and fine-tuned LLama models. This dataset encompasses a wide range of user-oriented instructions, spanning activities such as email composition, social media interactions, and utilization of productivity tools.
This model is often referred to as Alpaca or Alpaca-GPT3.
"We are excited to announce our discoveries regarding an instruction-following language model, named Alpaca, which has been fine-tuned from Meta’s LLaMA 7B model. Alpaca is trained on 52K instruction-following demonstrations, generated in the style of self-instruct using text-davinci-003. When evaluated on the self-instruct evaluation set, Alpaca exhibits behaviors akin to those of OpenAI’s text-davinci-003. Moreover, Alpaca proves to be surprisingly compact and cost-effective to reproduce."
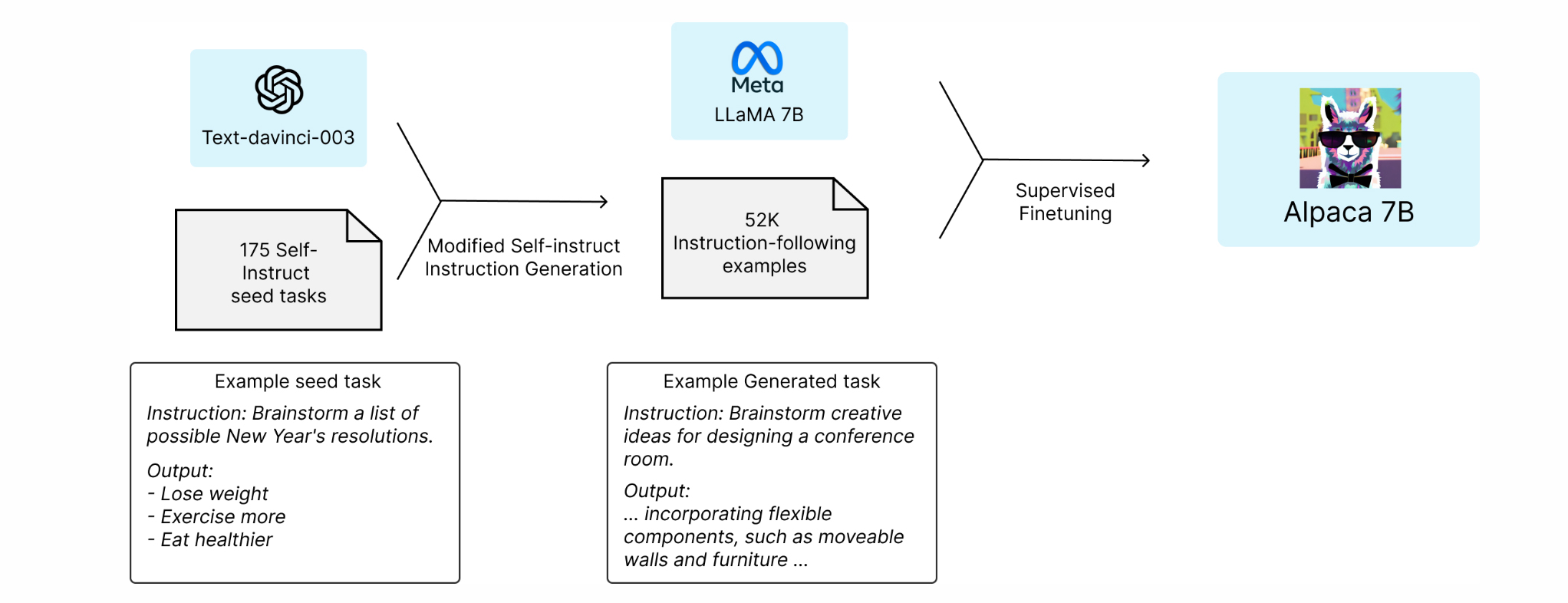
The Alpaca dataset and Alpaca-Llama model pipeline from
https://crfm.stanford.edu/2023/03/13/alpaca.html
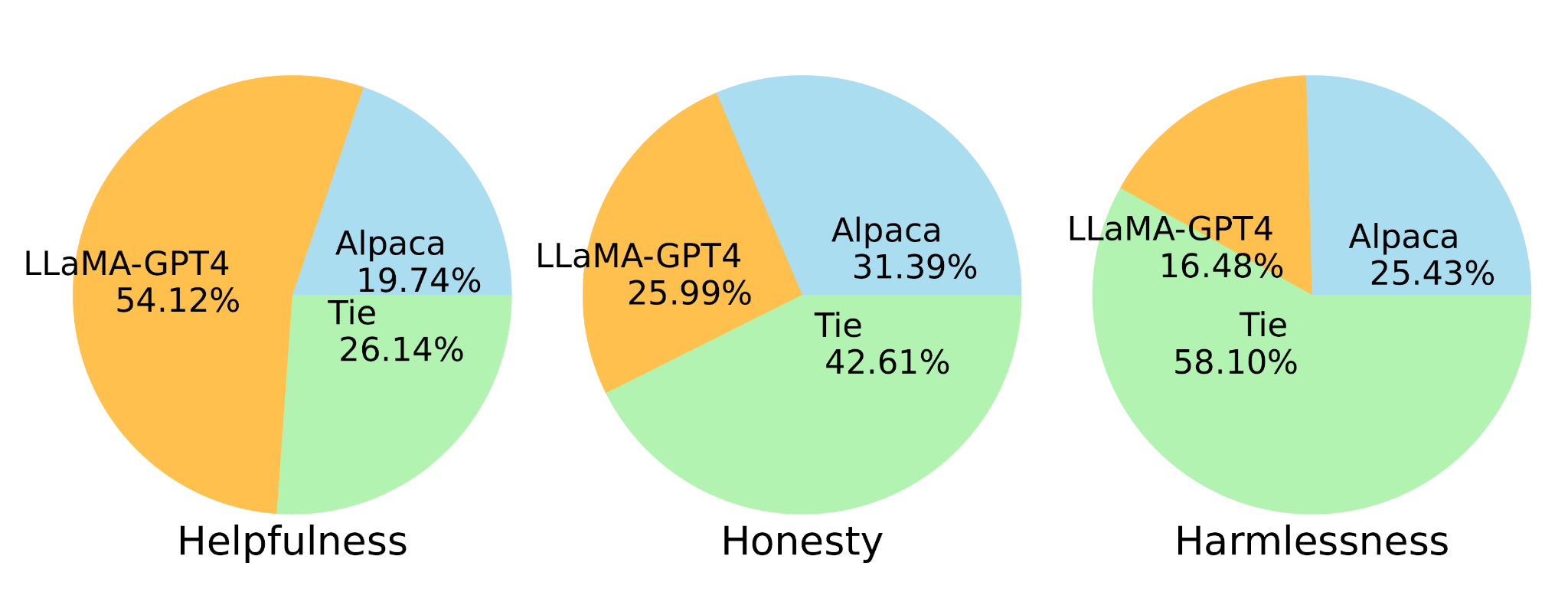
LLaMA-GPT-4 performs substantially better than LLaMA-GPT-3 in the "Helpfulness" criteria.
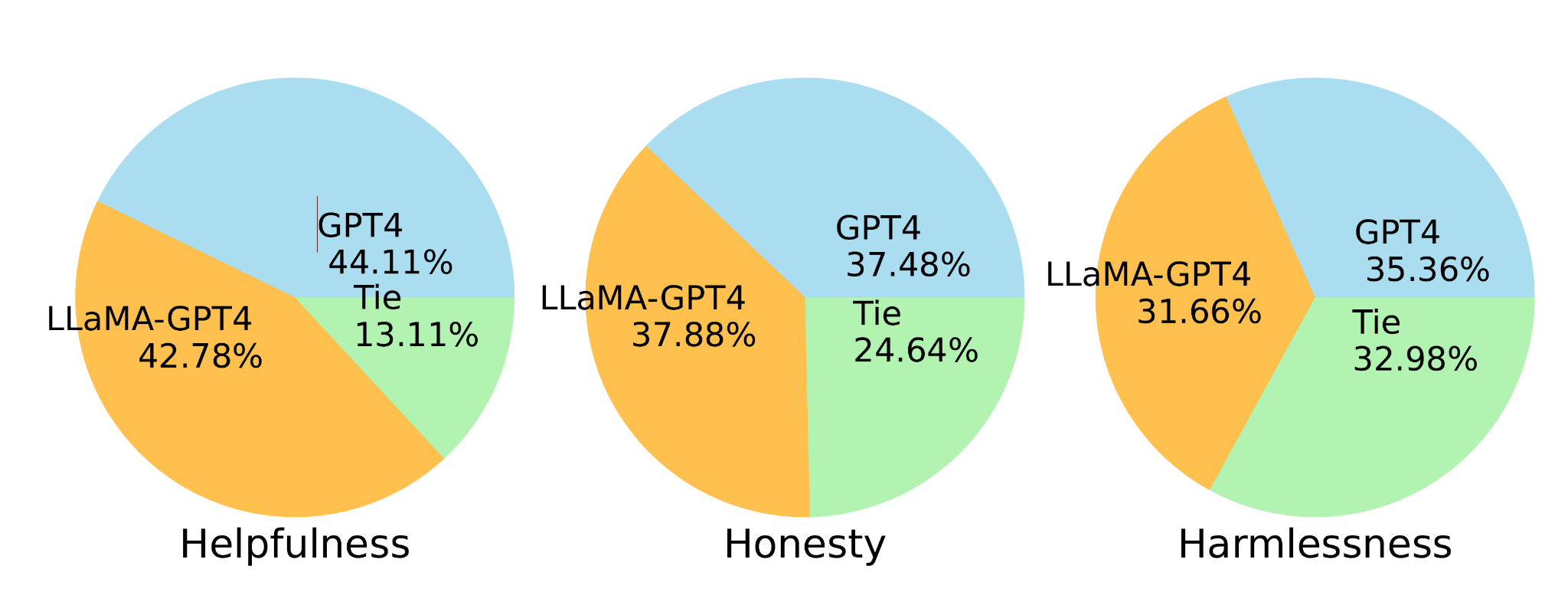
LLaMA-GPT-4 performs similarly to the original GPT-4 in all three criteria, suggesting a promising direction for developing state-of-the-art instruction-following LLMs.
The Alpaca-GPT4 Dataset
The Alpaca-GPT4 dataset consists of a single JSON file named alpaca_gpt4_data.json, containing 52K instruction-following data generated by GPT-4 with prompts in Alpaca style. This JSON file maintains the same format as the original Alpaca data, with the only difference being that the output is generated by GPT-4.
An example:
instruction: str, describes the task the model should perform. Each of the 52K instructions is unique.
input: str, optional context or input for the task.
output: str, the answer to the instruction as generated by GPT-4.
Log The Alpaca Dataset to W&B
See that code below. Also, as a reminder, all the code from this article can be found here.
import json
with open("alpaca_data.json", "r") as f:
alpaca = json.load(f)
with wandb.init(project="alpaca_ft"):
at = wandb.Artifact(
name="alpaca_gpt4",
type="dataset",
description="A GPT4 generated Alpaca like dataset for instruction finetunning",
metadata={"url":"https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM#how-good-is-the-data"},
)
at.add_file("alpaca_data.json")
# table
table = wandb.Table(columns=list(alpaca[0].keys()))
for row in alpaca:
table.add_data(*row.values())
Dataset preparation and tokenization
A row of the dataset (or one example) it’s a dictionary with keys: instruction, input, and output.
import json
with open("alpaca_data.json", "r") as f:
alpaca = json.load(f)
len(alpaca)
>> 52002
one_row = alpaca[232]
one_row = {
'instruction': 'What are the three primary colors?',
'input': '',
'output': 'The three primary colors are red, blue, and yellow.'
}
We need to do some preprocessing so we can feed the LLM with this data. Let’s define some functions to format the instructions:
def prompt_no_input(row):
return ("Below is an instruction that describes a task. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Response:\n").format_map(row)
def prompt_input(row):
return ("Below is an instruction that describes a task, paired with an input that provides further context. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n").format_map(row)
We have instructions with and without prompts, so we must deal with them separately. We could have concatenated the output simultaneously, but we will keep it separate as we will re-use these later on the instruction fine-tuning.
We get something that looks like this:
row = alpaca[232] print(prompt_input(row)) >> Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: What are the three primary colors? ### Input: ### Response:
def create_prompt(row):
return prompt_no_input(row) if row["input"] == "" else prompt_input(row)
prompts = [create_prompt(row) for row in alpaca] # all LLM inputs are here
End of String Token (EOS)
EOS_TOKEN = "</s>" EOS_TOKEN = "</s>" outputs = [row['output'] + EOS_TOKEN for row in alpaca]
outputs[0] # this is a oneliner split here for readability >> 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule.</s>'
dataset = [{"prompt":s, "output":t, "example": s+t} for s, t in zip(prompts, outputs)] You could store this preprocessed dataset as a W&B Artifact and avoid re doing this every time 😎
Tokens, tokens everywhere: How to tokenize and organize text
We need to convert the dataset into tokens. You can quickly do this with the workhorse of the transformers library, the Tokenizer! This function does a lot of heavy lifting besides tokenizing the text.
- It tokenizes the text
- Converts the outputs to PyTorch tensors
- Pads the inputs to match the length
- and more!
Let’s try that mighty tokenizer!
model_id = 'meta-llama/Llama-2-7b-hf' tokenizer = AutoTokenizer.from_pretrained(model_id) tokenizer.pad_token = tokenizer.eos_token
tokenizer.encode("My experiments are going strong!")
# >> [1, 1619, 15729, 526, 2675, 4549, 29991]
tokenizer.encode("My experiments are going strong!", padding='max_length', max_length=10)
# >> [1, 1619, 15729, 526, 2675, 4549, 29991, 2, 2, 2]
tokenizer.encode("My experiments are going strong!",
padding='max_length',
max_length=10,
return_tensors="pt")
# >> tensor([[ 1, 1619, 15729, 526, 2675, 4549, 29991, 2, 2, 2]])
Creating a Train-Eval Split
import random
random.shuffle(dataset). # shuffle inplace
train_dataset = dataset[:-1000]
eval_dataset = dataset[-1000:]
train_table = wandb.Table(dataframe=pd.DataFrame(train_dataset))
eval_table = wandb.Table(dataframe=pd.DataFrame(eval_dataset))
with wandb.init(project="alpaca_ft", job_type="split_data"):
wandb.log({"train_dataset":train_table, "eval_dataset":eval_table})
Packing: Combining multiple samples into a longer sequence
In order to enhance training efficiency and leverage the extended context capabilities of Large Language Models (LLMs), we’ll employ a technique known as “packing“. This involves consolidating multiple examples to occupy the model’s memory, thereby optimizing training efficiency instead of providing examples individually. By adopting this approach, we mitigate the need for extensive padding and handling of varying lengths.

After discussing with Lewis Tunstall 🤗 (one of the author's of the NLP with Transformers book), he pointed me out the more efficient way of doing this by actually packing sequences until a desired lenght and then feeding the model the packed-batch without need to pad with tokens.
max_seq_len = 1024
def pack(dataset, max_seq_len=1024):
tkds_ids = tokenizer([s["example"] for s in dataset])["input_ids"]
all_token_ids = []
for tokenized_input in tkds_ids:
all_token_ids.extend(tokenized_input + [tokenizer.eos_token_id])
packed_ds = []
for i in range(0, len(all_token_ids), max_seq_len+1):
input_ids = all_token_ids[i : i + max_seq_len+1]
if len(input_ids) == (max_seq_len+1):
packed_ds.append({"input_ids": input_ids[:-1], "labels": input_ids[1:]}) # < --- ‼️ ⛔️
# if you use the model.output.loss you don't need to shift, it is done for you!
return packed_ds
train_ds_packed = pack(train_dataset)
eval_ds_packed = pack(eval_dataset)
The amazing trl library has this implemented for us here.
Second Option: Batching multiple sequences of different lengths
There is another technique to construct batches from lines of different sizes; it’s by padding the sequences and making them longer so they can be batched together.
The tokenizer has a batching function that creates the batch from different samples and pads according to the desired strategy.
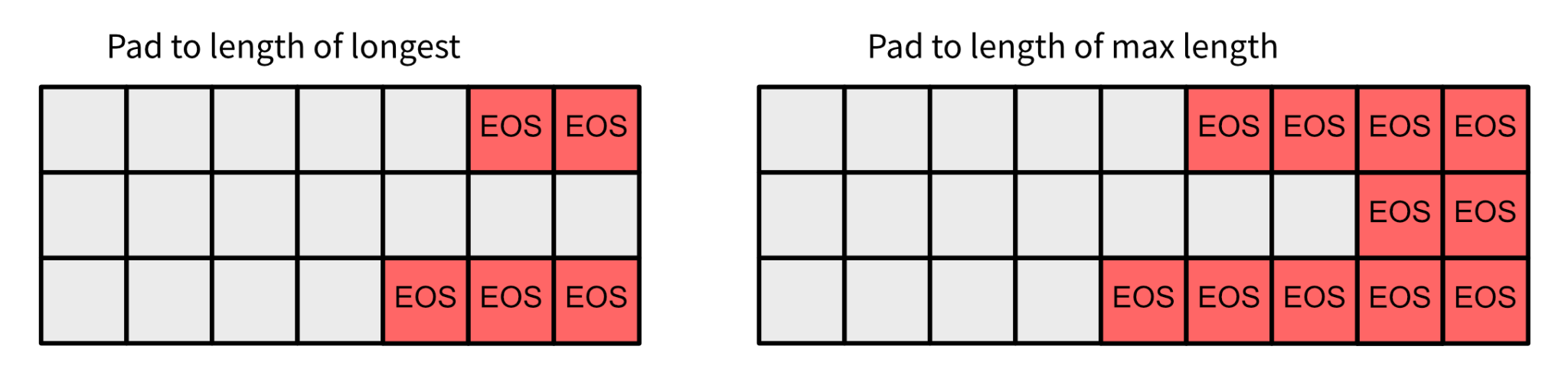
tokenizer(["My experiments are going strong!",
"I love Llamas"],
padding='longest',
return_tensors="pt")
>> {'input_ids': tensor([[ 1, 1619, 15729, 526, 2675, 4549, 29991],
[ 1, 306, 5360, 365, 5288, 294, 2]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 0]])}
tokenizer(["My experiments are going strong!",
"I love Llamas"],
# padding='max_length',
padding='max_length',
max_length=10,
return_tensors="pt")
>> {'input_ids': tensor([[ 1, 1619, 15729, 526, 2675, 4549, 29991, 2, 2, 2],
[ 1, 306, 5360, 365, 5288, 294, 2, 2, 2, 2]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0]])}
Storing our preprocessed datasets on W&B
import json
def save_jsonl(data, filename):
with open(filename, 'w') as file:
for entry in data:
json.dump(entry, file)
file.write('\n')
# dump everything to jsonl files
save_jsonl(train_ds_packed, "train_packed_alpaca.jsonl")
save_jsonl(eval_ds_packed, "eval_packed_alpaca.jsonl")
# Create a W&B artifact
packed_at = wandb.Artifact(
name="packed_alpaca",
type="dataset",
description="Alpaca dataset packed in sequences",
metadata={"max_seq_len":1024, "model_id":model_id})
packed_at.add_file("train_packed_alpaca.jsonl")
packed_at.add_file("eval_packed_alpaca.jsonl")
# log the artifact to the project, we can give this run a job_type like `preprocess`
with wandb.init(project="alpaca_ft", job_type="preprocess"):
wandb.log_artifact(packed_at)
The code for this article and the data pipeline can be found here
Conclusion and remarks
Good data serves as the foundation for exceptional models, and the formatting and preprocessing stages are pivotal in preparing datasets for fine-tuning tasks. These stages encompass numerous intricate details crucial for effectively instructing a model, coupled with various engineering nuances and techniques that streamline data flow and optimize GPU utilization.
Navigating the intricacies of tokenization and its interaction with text during batching and sequence creation can be challenging. This article aims to provide essential insights into this process, empowering you to fine-tune models using a state-of-the-art script that simplifies complexity. Armed with this knowledge, you can approach the task with confidence, knowing that the process should proceed smoothly.
With our preprocessed dataset readily available in the project’s Artifacts panel, we can seamlessly access it and commence the fine-tuning process without delay. This accessibility streamlines the workflow, enabling efficient model training and iteration.